Suite à discrépance faible
En mathématiques, une suite à discrépance faible est une suite ayant la propriété que pour tout entier N, la sous-suite x1, ..., xN a une discrépance basse.
Dans les faits, la discrépance d'une suite est faible si la proportion des points de la suite sur un ensemble B est proche de la valeur de la mesure de B, ce qui est le cas en moyenne (mais pas pour des échantillons particuliers) pour une suite équidistribuée. Plusieurs définitions de la discrépance existent selon la forme de B (hypersphères, hypercubes, etc.) et la méthode de calcul de la discrépance sur B.
Les suites à discrépance faible sont appelées quasi aléatoires ou sous-aléatoires, en raison de leur utilisation pour remplacer les tirages de la loi uniforme continue. Le préfixe « quasi » précise ainsi que les valeurs d'une suite à discrépance faible ne sont pas aléatoires ou pseudo-aléatoires, mais ont des propriétés proches de tels tirages, permettant ainsi leur usage intéressant dans la méthode de quasi-Monte-Carlo.
Définitions
Discrépance
La discrépance ou discrépance extrême[1] d'un ensemble P = {x1, ..., xN} est définie (en utilisant les notations de Niederreiter) par

avec
- λs est la mesure de Lebesgue de dimension s,
- A(B; P) est le nombre de points de P appartenant à B,
- J est l'ensemble des pavés de dimension s, de la forme

avec .

Discrépance à l'origine et discrépance isotrope
La discrépance à l'origine D*N(P) est définie de façon similaire, mis à part que la borne inférieure des pavés de J est fixée à 0 :

avec J* l'ensemble des pavés de dimension s, de la forme

où ui est dans l'intervalle semi-ouvert [0, 1[.
On définit également la discrépance isotrope JN(P) :

avec la famille des sous-ensembles convexes du cube unité fermé de dimension s.

On a les résultats suivants
- ,
- ,
- .



Propriétés
L'inégalité de Koksma-Hlawka
On note Īs le cube unitaire de dimension s,
- .
![{\displaystyle {\bar {I}}^{s}=[0,1]\times ...\times [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c072667f5e22ae66fbac84f2b8de60e181e5833c)
Soit f une fonction à variation bornée de variation de Hardy-Krause V(f) finie sur Īs. Alors pour tout x1, ..., xN dans Is = [0, 1[ × ... × [0, 1[
- .

L'inégalité de Koksma-Hlawka est consistante dans le sens où pour tout ensemble de points x1,...,xN dans Is et tout ε > 0, il existe une fonction f à variation bornée telle que V(f)=1 et

Ainsi, la qualité du calcul de l'intégrale ne dépend que de la discrépance D*N(x1,...,xN).
L'inégalité d'Erdös-Turán-Koksma
Article détaillé : Inégalité d'Erdős–Turán.
Le calcul de la discrépance de grands ensembles est souvent compliquée, mais l'inégalité d'Erdös-Turán-Koksma donne une majoration de la valeur.
Soit x1,...,xN des points sur Is et H un entier positif. Alors
avec


Conjectures sur la minoration des valeurs de la discrépance
Conjecture 1. Il existe une constante cs dépendant uniquement de la dimension s, telle que

pour tout ensemble fini de points {x1,...,xN}.
Conjecture 2. Il existe une constante c's dépendant uniquement de la dimension s, telle que

pour au moins un sous-ensemble fini de valeurs de la suite x1, x2, x3....
Ces conjectures sont équivalentes. Si elles ont été prouvées pour s ≤ 2 par Wolfgang Schmidt, la question des dimensions supérieures est encore ouverte.
Minorations connues
Soit s = 1. Alors

pour tout N et toute suite de valeurs {x1, ..., xN}.
Soit s = 2. Wolfgang Schmidt a prouvé que pour tout ensemble fini de points {x1, ..., xN}, on a

avec

Pour les dimensions s > 1, K. F. Roth a prouvé que

pour tout ensemble fini de points {x1, ..., xN}.
Construction de suites à discrépance faible
On ne donne ici que des exemples de tirages à discrépance faible pour les dimensions supérieures à 1.
On sait construire des suites telles que

où la constante C dépend de la suite. Par la conjecture 2, ces suites sont supposées avoir le meilleur ordre de convergence possible.
À partir de nombres aléatoires
Des suites de nombres sous-aléatoires peuvent être générées à partir d'un tirage aléatoire en imposant une corrélation négative entre les nombres du tirage. Par exemple, on peut se donner un tirage aléatoire ri sur et construire des nombres sous-aléatoires si réparties de façon uniforme sur par :


- si i impair et si i pair
- .



Par récurrence additive
Une méthode classique de génération de nombres pseudo-aléatoires est donné par[2] :
- .

En fixant a et c à 1, on obtient un générateur simple :
- .

Suites de Sobol
La variante Antonov–Saleev de la suite de Sobol génère des nombres entre 0 et 1 comme fractions binaires de longueur w, pour un ensemble w fractions binaires spéciales, sont appelés nombres de direction. Les bits du code de Gray de i, G(i), sont utilisés pour choisir des nombres de direction. Obtenir les valeurs de la suite de Sobol si demande le ou exclusif de la valeur binaire du code de Gray de i avec le nombre de direction approprié. Le nombre de dimension a un impact sur le choix de Vi.

Suites de van der Corput
Article détaillé : Suite de van der Corput.
Soit

la décomposition de l'entier positif n ≥ 1 en base b, avec donc 0 ≤ dk(n) < b. On pose

Alors il existe une constante C dépendant uniquement de b telle que (gb(n))n ≥ 1 vérifie

Suite de Halton
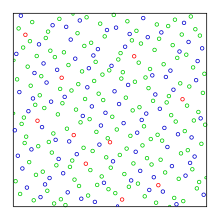
La suite de Halton généralise la suite de van der Corput pour les dimensions supérieures à 1. Soit s la dimension du problème et b1, ..., bs des nombres premiers entre eux supérieurs à 1. Alors

Il existe une constante C dépendant uniquement de b1, ..., bs, telle que {x(n)}n≥1 vérifie

Dans la pratique, on utilise les s premiers nombres premiers pour b1, ..., bs.
Suite de Hammersley

Soit b1,...,bs-1 des nombres premiers entre eux supérieurs à 1. Pour s et N donnés, la suite de Hammersley de taille N est donnée par

Elle vérifie

où C est une constante ne dépendant que de b1, ..., bs−1.
Références
(en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Low-discrepancy sequence » (voir la liste des auteurs).
- ↑ Discrepancy en anglais, voir par exemple (Lapeyre et Pagès 1989) et (Thiémard 2000), pour une référence de la traduction.
- ↑ (en) Donald E. Knuth, The Art of Computer Programming, vol. 2, chap. 3.
Bibliographie
Théorie
- Eric Thiémard, Sur le calcul et la majoration de la discrépance à l'origine (Thèse de doctorat), École polytechnique fédérale de Lausanne, (lire en ligne)

- (en) Josef Dick et Friedrich Pillichshammer, Digital Nets and Sequences. Discrepancy Theory and Quasi-Monte Carlo Integration, Cambridge University Press, Cambridge, 2010, (ISBN 978-0-521-19159-3)
- (en) L. Kuipers et H. Niederreiter, Uniform distribution of sequences, Dover Publications, , 416 p. (ISBN 0-486-45019-8)
- (en) Harald Niederreiter, Random Number Generation and Quasi-Monte Carlo Methods, SIAM, 1992 (ISBN 0-89871-295-5)
- (en) Michael Drmota et Robert F. Tichy, Sequences, discrepancies and applications, Lecture Notes in Math., 1651, Springer, Berlin, 1997 (ISBN 3-540-62606-9)
- Bernard Lapeyre et G. Pagès, « Familles de suites à discrépance faible obtenues par itération de transformations de [0, 1] », Note aux CRAS, Série I, vol. 17, , p. 507-509
Simulations numériques
- (en) William H. Press, Brian P. Flannery, Saul A. Teukolsky et William T. Vetterling, Numerical Recipes in C, Cambridge University Press, 2e éd., 1992 (ISBN 0-521-43108-5) (voir Section 7.7 pour une discussion moins technique)
- Quasi-Monte Carlo Simulations, http://www.puc-rio.br/marco.ind/quasi_mc.html
Liens externes
- (en) Collected Algorithms of the ACM (voir les algorithmes 647, 659 et 738)
- (en) GNU Scientific Library Quasi-Random Sequences
 Portail des mathématiques
Portail des mathématiques









